
Why Does it Look Like that?
While there is a host of planetary, political, ethical, public policy, and even pedagogical issues at stake with the latest rapidly improving crop of artificial intelligence platforms, running the gamut from existential risk through labor malpractice, disinformation and data ethics, the first question I want to get straight on is a formal yet fundamental one: why do AI generated images look the way they do?

In particular, why are the aesthetics of fantasy, steampunk, anime, kawaii, 3D game engines yet also analogue photography and traditional cinematic lighting so prevalent? Why does everything look like a still from a Netflix show? And why do people’s faces conform to Hollywood beauty norms while limbs are often horribly contorted, hands deformed, and digits miscounted?
The images in Fig. 1, above, used to promote Stable Diffusion, an open source AI project, maintained and funded chiefly by Stability AI, a VC-backed private company based in London, have clearly been carefully considered and curated. Perhaps the set of images merely reflects the averaged taste of the open source enthusiasts who maintain the code repository on Github, a platform for hosting and managing such open source projects? Perhaps. If so, I really want to ask: who the hell are they?!
A useful structuralist tactic here is to probe the default settings and default visual outputs. The images I created below in Fig. 2.1-2.5 are just that. I took a found list of keywords, prompted Midjourney’s latest default model 5.2 with a single word prompt and left all settings on default. No further keywords, no image prompts, no negative prompts, no so-called ‘prompt-engineering’ of any kind. Here they are…





They are kind of amazing yet also homogenous and boring at the same time. They are slick, glossy, hyper-sexualized, fantastical, surreal, moody, well-lit, well composed if excessively symmetrical, suffused with pinks and reds, also schlocky, kitschy, internetty—to a relentless and nauseating degree—there are cats, cosplay costumes, and lots of pale-colored people.
So you might simply conclude: ‘It’s the internet, stoopid!’ People are bad. Their internet is worse. If you chuck it all in a blender with the discontents of neo-liberal capitalism (will it blend?) this kind of well-packaged goop is exactly what you should expect. Serves you right!
I certainly think this sort of answer is a start. But I want to ask: which nodes of the sprawling web are being exaggerated and which neglected? Where and when and how do predilections, tastes, values, biases, points of view, not to mention certain object fetishes and paraphilias, enter the circuits? How might we locate them, challenge them, redress them?
Bias against Minoritized Groups
You may well ask at this point, as several researchers and artists have since the late 2010’s, why and how do certain visual biases pertaining to minoritized people frequently emerge in AI generated imagery? Inmates and drug dealers are black, terrorists are muslim, people with autism have curly hair, kinksters are men who sit on red leather wingback chairs while voyeurs are young women who stand uneasily amidst drapes of turquoise velvet.
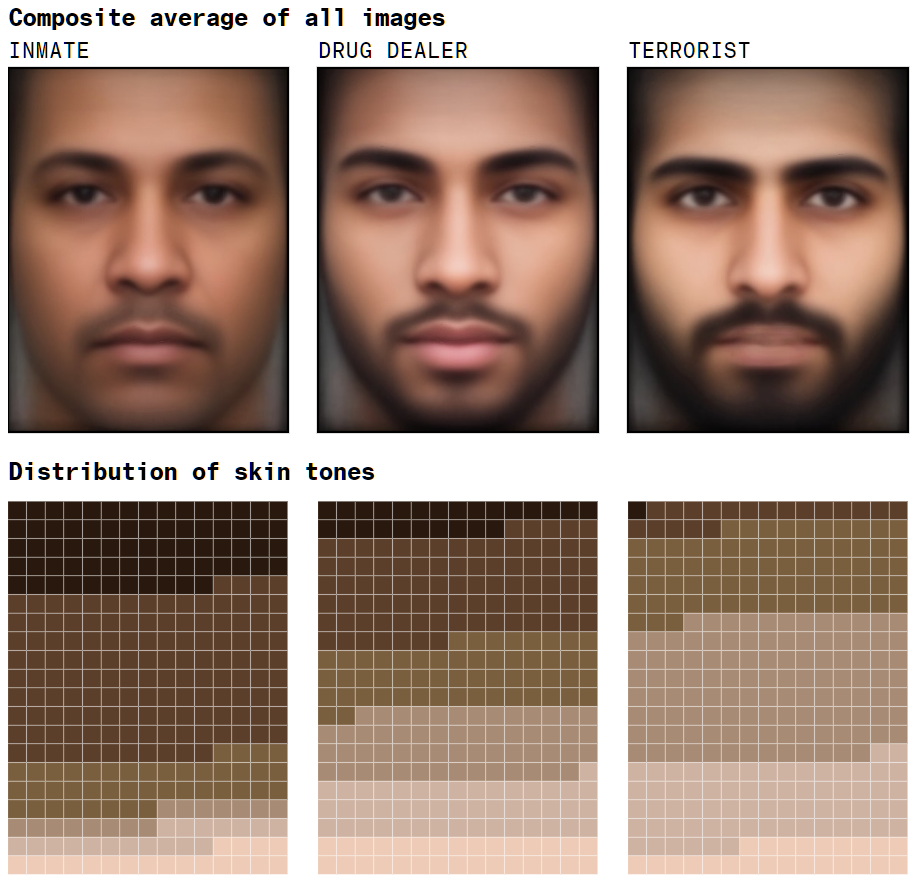
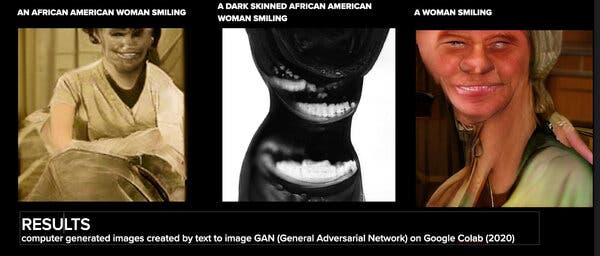


Not only do machine learning platforms predict the incarcerated to be black (Fig. 3.1), their representations of dark-skinned people are significantly more likely to be malformed (Fig. 3.2), they assume that people with blond hair extensions have lighter skin tones (Fig 3.3), and that questions about race are always questions about blackness, not white privilege. (Fig. 3.4)
The issues are real, complex, pernicious, and well-documented.
Stable Diffusion
I’m going to explore the Stable Diffusion platform only here, for the good reason that the data used for training its model and the model itself are open source, and some documentation of it already exists. Stable Diffusion is a deep learning, generative machine learning model, specifically a latent image diffusion model, capable of generating images, in photorealistic or other styles, in response to textual descriptions, popularly known as ‘prompts’. The project is maintained and funded chiefly by Stability AI, a VC-backed private company based in London, which is as yet adhering to an open source model.
In contrast, similar platforms Midjourney (Midjourney, Inc.), DALL-E (OpenAI, Inc.), and Imagen (Alphabet Inc.) are owned by private and public corporations who fiercely maintain trade secrecy around their allegedly proprietary intellectual property via a number of different legal and labor practices and for a number of different reasons, mostly specious. I say ‘allegedly’ because most of these platforms use the the same open source image dataset as Stable Diffusion, namely LAION-5B, scraped from the internet at large with no stakeholder’s consent, published by the German non-profit organization LAION (an acronym for Large-scale Artificial Intelligence Open Network), which is funded mostly by Stability AI, and which is notably embroiled in a number of class action lawsuits with artists, designers and other corporations who allege that LAION infringed their copyright by ingesting their images into its dataset without the parties’ informed consent.
LAION-5B
LAION-5B is an open source dataset of 5.85 billion image-caption pairs extracted from the Common Crawl, which itself is an open source repository of the content of the entire public domain internet.
Stable Diffusion is actually trained on low-resolution 256×256 images from LAION-2B-EN, a subset of 2.3 billion English-captioned images from LAION-5B‘s full collection of 5.85 billion image-text pairs, as well as LAION-High-Resolution, another subset of LAION-5B with 170 million images greater than 1024×1024 resolution.
So yes, it’s the internet, stupid, or rather a colonial, linguistically etiolated, image-centric version thereof.
So far, so interesting.
LAION-Aesthetics-V2
Here’s where it gets really interesting though – at least from my formal point of view, asking why images generated on Stable Diffusion look, especially by default, the way that they do.
So, although Stable Diffusion’s latest models (1.5, SDXL, 1.6) were trained initially on LAION-2B-EN and LAION-High-Resolution, they were fine-tuned on LAION-Aesthetics-V2. Specifically, the last three checkpoints, “were [trained] on LAION-Aesthetics-v2 5+, a 600 million image subset of LAION-2B-EN with a predicted aesthetics score of 5 or higher”.
What on earth is “a predicted aesthetics score of 5 or higher”?

Turns out, it’s an algorithmic prediction that someone would rate a given image as ‘5’ or above if asked “How much do you like this image on a scale from 1 to 10?”
So we can confidently say here that the complex of aesthetic and/or artistic values has been simplistically reduced to the single concept of human likability, whatever that is, with an unsettlingly unspecified human subject. This is very much not the internet, then, but rather that subset of it that ‘humans’ are predicted to ‘like’, a monocultural puddle of machine-predicted behavioural data.
If you want to see what the subset of LAION-2B images predicted to score 5 or more out of 10 (2B-EN-5) look like, Christoph Schumann, organizational lead and co-founder of LAION, has published a selection on his personal website. Examples predicted to score 6.5 or more out of 10, the highest usable threshold, 2B-EN-6.5, are illustrated in Fig. 4 above.
Cultural critic Andy Baio and software engineer Simon Willison have explored more thoroughly the LAION-Aesthetics-V2 subset known as 2B-EN-6 and have even rendered its images searchable online at datasette.io. 2B-EN-6 contains a more manageable 12 million image-text pairs with a predicted aesthetic score of 6 or higher, instead of the 600 million rated 5 or higher used in Stable Diffusion’s late-stage fine-tuning.
Fig. 4, above, is representative of the type of images making it through this high pass filter: landscapes, streetscapes, portraits of women, mostly in a whimsical, nostalgic, watercolory or slightly cartoonish style.
Next question. What is this algorithm that predicts what images humans will like? How was it trained? On what datasets? I provide a short excursion down this rabbit hole, below, identifying the three main image datasets which were used to train LAION’s likability algorithm.
I – Simulacra Aesthetic Captions (SAC) Dataset
SAC is a dataset of over 238,000 synthetic images generated with AI models such as Stable Diffusion. The images have been rated from 1 to 10 by users. This is simply raw behavioral data that has been harvested, but, wow, just look at the imagery in Fig. 5.1, below.

Futuristic cartoons of cats and robots! Where is the human figure? Where is everyday life?
II – Aesthetic Visual Analysis (AVA) Dataset
AVA is a dataset of over 250,000 digital photographs from dpchallenge.com, a site that hosts weekly contests for digital photographers. The photographs are permitted to be digitally manipulated with image processing software and are rated on their aesthetic value from 1 to 10 by multiple users on the site in a popular vote. All-time top-voted images are excerpted below in Fig 5.2.

Artsy landscapes, quasi-reportage computationally manipulated to monochrome, clever close-ups at high and low shutter speed, packshots. Where is the human body, where is the family snapshot, where is Steyerl’s “poor image”, where is lighting beyond sunrise, sunset, and the photographer’s studio?
III – LAION Logo Dataset
Just when you thought things couldn’t really get much flatter, LAION supplements these two very specific forms of kitsch with memes and motivational posters. OK, I’m joking, but it’s actually weirder, narrower, and more intensely neoliberal than that. The third set of images used to train LAION’s likability algorithm is a collection of 15,000 brand and product logos which some unspecified group of people, most likely workers in sub-Saharan outsource centers, have rated from 1 to 10.

Um, do 21st century humans in the global north like images better if they look more like successful brand logos? That’s the implicit assumption.
Conclusion
Stable Diffusion, by default, seems deliberately engineered to generate images that tend towards:
- futuristic fantasy, sci-fi anime, and nostalgic whimsy
- the traditional, analog yet overly post-processed aesthetic admired by hobbyist and professional photographers shooting on DSLRs
- the look of shopping malls, logo-adorned apparel, stickers, and ecommerce sites
Other popular platforms – Midjourney, DALL-E, and Imagen – may be more or less opinionated and in quite different ways. My personal experience is that Midjourney’s model 5.2 seems to lean strongly to the look of the Simulacra Aesthetic Captions Dataset, unless you switch the model to ‘Niji 5’ in which case you go full-blown anime. I make special mention of Midjourney because it is the platform used most frequently by practicing artists.